
La synchronicité est trop parfaite pour être anodine. Le même jour, à quelques heures d’intervalle, Anthropic et OpenAI ont levé le voile sur leurs nouveaux modèles les plus avancés, Claude Opus 4.6 d’un côté, GPT-5.3 Codex de l’autre. Deux annonces simultanées qui traduisent une chose, la compétition entre laboratoires d’IA est désormais entrée dans une phase d’escalade continue, où chaque amélioration de performance devient un signal stratégique autant qu’un progrès technologique.
Ces deux modèles incarnent une même ambition, franchir un nouveau seuil dans les capacités agentiques de l’IA, mais avec des philosophies très différentes. Là où Anthropic poursuit une approche généraliste orientée vers le travail intellectuel complexe, OpenAI assume une spécialisation radicale autour du développement logiciel et de l’automatisation informatique.
Deux stratégies, un même objectif, dominer l’IA agentique
Claude Opus 4.6 marque une évolution majeure dans la feuille de route d’Anthropic. Le modèle dispose désormais d’une fenêtre de contexte pouvant atteindre un million de tokens, contre 200 000 pour Opus 4.5. Concrètement, cela lui permet d’analyser l’équivalent de plusieurs centaines de pages techniques, juridiques ou scientifiques sans perte de cohérence, un atout décisif pour les usages professionnels à forte densité informationnelle.
Anthropic introduit également la notion d’équipes d’agents, plusieurs instances du modèle capables de collaborer en parallèle sur une même tâche. Cette approche s’inspire directement du fonctionnement des équipes humaines, avec une répartition des sous-tâches, une coordination interne et une agrégation finale des résultats.
De son côté, OpenAI adopte une trajectoire beaucoup plus ciblée avec GPT-5.3 Codex. Le modèle est entièrement optimisé pour le développement logiciel, l’exécution de commandes système et l’usage autonome d’un ordinateur. Il ne cherche pas à être polyvalent, mais redoutablement efficace dans un périmètre précis, celui du code et de l’automatisation technique.
Des performances qui rebattent les cartes du marché
Les benchmarks publiés par les deux entreprises illustrent cette divergence stratégique.
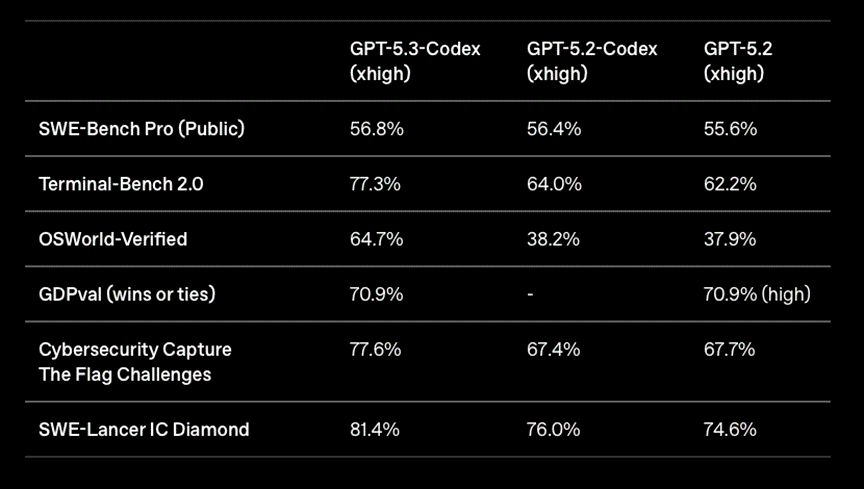
© OpenAI
Sur Terminal-Bench 2.0, qui mesure la capacité d’un agent à coder et à interagir de manière autonome avec un environnement informatique, GPT-5.3 Codex atteint 77,3 %, contre 64,0 % pour GPT-5.2 Codex. Sur OSWorld-Verified, un benchmark évaluant l’usage autonome d’un ordinateur réel, le score bondit de 38,2 % à 64,7 %, soit une progression de plus de 26 points. OpenAI revendique également une exécution 25 % plus rapide, rendue possible par des optimisations profondes de son infrastructure.
Claude Opus 4.6, lui, se distingue sur un spectre plus large de compétences.
{kind=link}
Le modèle 4.6 atteint 65,4 % sur Terminal-Bench 2.0, devant GPT-5.2 et Gemini 3 Pro, mais surtout 68,8 % sur ARC-AGI 2, un test conçu pour évaluer le raisonnement abstrait sur des problèmes simples pour l’humain mais complexes pour les machines, contre 37,6 % pour Opus 4.5. Sur Finance Agent, dédié à l’analyse financière complexe, Opus 4.6 obtient 60,7 %, confirmant son positionnement sur les tâches à forte valeur cognitive.
Généraliste contre spécialiste, deux visions de la productivité IA
Cette confrontation met en lumière un choix stratégique fondamental. Claude Opus 4.6 vise à devenir un assistant intellectuel universel, capable de naviguer entre analyse juridique, recherche scientifique, rédaction stratégique et modélisation financière. GPT-5.3 Codex, à l’inverse, s’impose comme un outil de production logicielle, pensé pour s’intégrer directement dans les environnements de développement et automatiser des chaînes entières de tâches techniques.
Dans les benchmarks de codage pur, Codex conserve un avantage net. Dans les tâches multidisciplinaires, Opus prend l’ascendant. Pour les entreprises, le choix ne se fera donc pas sur la performance brute, mais sur l’adéquation entre le modèle et les flux de travail réels.
Des gains spectaculaires, mais à quel coût ?
Cette montée en puissance pose une question centrale, celle du coût opérationnel. Claude Opus 4.6 maintient un tarif de 5 dollars par million de tokens en entrée, mais l’utilisation de la fenêtre de contexte étendue entraîne une majoration sensible. GPT-5.3 Codex est réservé aux abonnés payants de ChatGPT et mise sur une intégration étroite avec les outils existants, plutôt que sur une tarification à l’usage explicitement affichée.
Ces modèles consomment des ressources massives en calcul et en énergie, ce qui limite, pour l’instant, leur accessibilité aux acteurs disposant de moyens conséquents. L’IA frontière reste un outil de pointe, pas encore un standard universel.
Une course qui redéfinit le futur de l’IA professionnelle
La sortie simultanée de Claude Opus 4.6 et GPT-5.3 Codex illustre une transformation profonde du paysage de l’IA. Nous ne sommes plus dans une logique d’amélioration incrémentale, mais dans une course à l’agentivité, où les modèles ne se contentent plus de répondre, ils planifient, exécutent et collaborent.
À court terme, cette rivalité accélère l’innovation. À moyen terme, elle pose des questions cruciales sur la gouvernance, la dépendance technologique et la place de l’humain dans des chaînes de décision de plus en plus automatisées. La guerre des modèles frontières ne fait que commencer, et elle façonne déjà l’architecture du travail intellectuel de demain.
Pour aller plus loin
Cette bataille de modèles de nouvelle génération illustre la compétition intense entre géants de l’IA autour des capacités frontier, qu’il s’agisse d’agents autonomes, de raisonnement profond ou d’automatisation des workflows techniques. Pour approfondir la manière dont l’IA redéfinit les capacités cognitives et productives des systèmes intelligents, retrouvez notre article « GPT-OSS : OpenAI publie ses premiers modèles open source depuis 2019 », qui explore le rôle de l’open source dans l’évolution des modèles d’IA et leur accessibilité, ainsi que les implications stratégiques de l’ouverture des technologies de pointe.
Références
1. Anthropic. (2026). Claude Opus 4.6 Technical Overview.
https://www.anthropic.com
2. OpenAI. (2026). GPT-5.3 Codex System Card and Benchmarks.
https://openai.com
3. Chollet, F. et al. (2024). ARC-AGI: Measuring Abstract Reasoning in AI Systems.
https://arcprize.org
4. OSWorld Consortium. (2025). Evaluating Autonomous Agents in Realistic Computer Environments.
https://osworld.ai
