
The timing is too perfect to be a coincidence. On the same day, just hours apart, Anthropic and OpenAI unveiled their most advanced new models: Claude Opus 4.6 on one side, and GPT-5.3 Codex on the other. These two simultaneous announcements signal one thing: competition among AI labs has now entered a phase of continuous escalation, where every performance improvement becomes as much a strategic signal as it is a technological advancement.
These two models share the same goal—to reach a new milestone in AI’s agentic capabilities—but they are guided by very different philosophies. While Anthropic takes a generalist approach focused on complex intellectual tasks, OpenAI has adopted a radical specialization in software development and IT automation.
Two strategies, one goal: to dominate agent-based AI
Claude Opus 4.6 marks a major milestone in Anthropic’s roadmap. The model now features a context window of up to one million tokens, compared to 200,000 in Opus 4.5. In practical terms, this allows it to analyze the equivalent of several hundred technical, legal, or scientific pages without losing coherence—a decisive advantage for professional applications involving high information density.
Anthropic also introduces the concept of agent teams—multiple instances of the model capable of collaborating in parallel on the same task. This approach is directly inspired by how human teams operate, involving the division of subtasks, internal coordination, and the final aggregation of results.
For its part, OpenAI is taking a much more focused approach with GPT-5.3 Codex. The model is fully optimized for software development, executing system commands, and autonomous computer use. It does not aim to be versatile, but rather highly effective within a specific scope: coding and technical automation.
Performance that is reshaping the market
The benchmarks published by the two companies illustrate this strategic divergence.
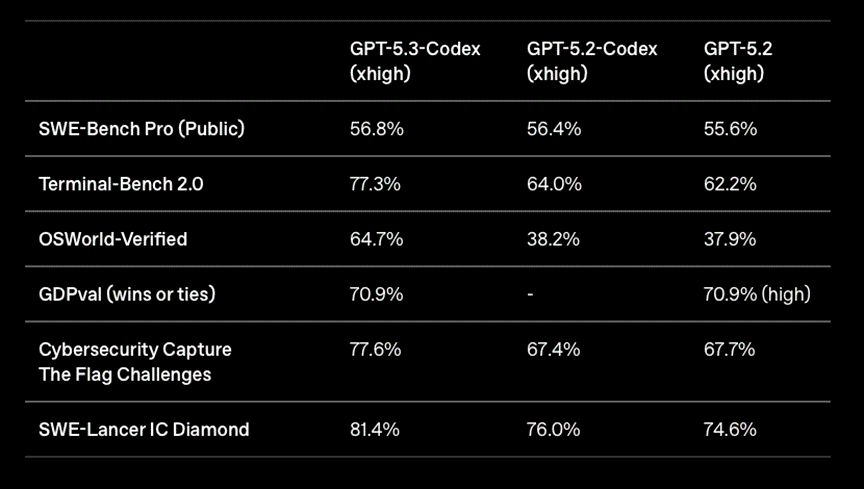
© OpenAI
On Terminal-Bench 2.0, which measures an agent’s ability to code and interact autonomously with a computing environment, GPT-5.3 Codex achieved a score of 77.3%, compared to 64.0% for GPT-5.2 Codex. On OSWorld-Verified, a benchmark assessing autonomous use of a real computer, the score jumps from 38.2% to 64.7%, an increase of more than 26 points. OpenAI also claims a 25% faster execution time, made possible by deep optimizations to its infrastructure.
Claude Opus 4.6, on the other hand, stands out across a broader range of capabilities.
{kind=link}
Model 4.6 achieved a score of 65.4% on Terminal-Bench 2.0, outperforming GPT-5.2 and Gemini 3 Pro, but more notably, it scored 68.8% on ARC-AGI 2—a test designed to assess abstract reasoning on problems that are simple for humans but complex for machines—compared to 37.6% for Opus 4.5. On Finance Agent, a benchmark dedicated to complex financial analysis, Opus 4.6 achieves 60.7%, confirming its strength in tasks requiring high cognitive value.
Generalists vs. Specialists: Two Perspectives on AI Productivity
This comparison highlights a fundamental strategic choice. Claude Opus 4.6 aims to become a universal intellectual assistant, capable of navigating between legal analysis, scientific research, strategic writing, and financial modeling. GPT-5.3 Codex, on the other hand, is establishing itself as a software development tool, designed to integrate directly into development environments and automate entire chains of technical tasks.
In pure coding benchmarks, Codex maintains a clear advantage. In multidisciplinary tasks, Opus takes the lead. For businesses, the choice will therefore not be based on raw performance, but on how well the model aligns with real-world workflows.
Spectacular gains, but at what cost?
This ramp-up raises a key question: that of operational costs. Claude Opus 4.6 maintains a rate of $5 per million input tokens, but using the extended context window results in a significant increase. GPT-5.3 Codex is reserved for paying ChatGPT subscribers and focuses on tight integration with existing tools, rather than on explicitly stated pay-per-use pricing.
These models consume massive amounts of computational resources and energy, which currently limits their accessibility to organizations with substantial resources. State-of-the-art AI remains a cutting-edge tool, not yet a universal standard.
A race that is redefining the future of professional AI
The simultaneous release of Claude Opus 4.6 and GPT-5.3 Codex underscores a profound transformation in the AI landscape. We are no longer in an era of incremental improvement, but in a race toward agency, where models no longer merely respond—they plan, execute, and collaborate.
In the short term, this rivalry is driving innovation. In the medium term, it raises crucial questions about governance, technological dependence, and the role of humans in increasingly automated decision-making processes. The battle over business models has only just begun, and it is already shaping the future of intellectual work.
Learn more
This battle among next-generation models highlights the intense competition among AI giants over cutting-edge capabilities, whether in autonomous agents, deep reasoning, or the automation of technical workflows. To learn more about how AI is redefining the cognitive and productive capabilities of intelligent systems, read our article“GPT-OSS: OpenAI Releases Its First Open-Source Models Since 2019, ” which explores the role of open source in the evolution of AI models and their accessibility, as well as the strategic implications of opening up cutting-edge technologies.
References
1. Anthropic. (2026). Claude Opus 4.6 Technical Overview.
https://www.anthropic.com
2. OpenAI. (2026). GPT-5.3 Codex System Card and Benchmarks.
https://openai.com
3. Chollet, F. et al. (2024). ARC-AGI: Measuring Abstract Reasoning in AI Systems.
https://arcprize.org
4. OSWorld Consortium. (2025). Evaluating Autonomous Agents in Realistic Computer Environments.
https://osworld.ai
