



By Anuradha Kar, Associate Professor of AI & Robotics at aivancity
Introduction
As the domain of artificial intelligence continues to evolve at a rapid pace, it’s not just researchers in labs or company engineers who are pushing boundaries—young students also play a vital role in driving AI innovation by bringing fresh perspectives, curiosity, and bold experimentation. When engaged in hands-on projects and research, they challenge conventional methods, explore untapped ideas, and often pioneer creative solutions. Their passion and adaptability make them key contributors to shaping the future of artificial intelligence.
This year, I integrated hands-on projects into my Deep Learning for Computer Vision (DLCV) course for the first-year Master’s cohort (equivalent to the fourth year of the Grande École programme). After working through a semester, the students delivered an outstanding range of projects that were both technically ambitious and socially meaningful, with strong ties to real-world applications.
What makes their works even more commendable is that these projects were conceived and completed by the students within the short timeframe of continuous assessment (as we call them “contrôle continu”) as part of the DLCV course for this semester. Each student proposed their own project idea and developed it independently within a period of three months—guided by iterative discussions and feedback which I included as part of my DLCV lectures. My role as a mentor was to advise, challenge, and support their thinking while ensuring their original ideas remained at the heart of their work.
Below I share some of the details and outcomes of these projects, highlighting the students’ creativity, technical skills, and their ability to apply deep learning to meaningful, real-world challenges.
From ideas to impact: Student project spotlights
Here’s a glimpse into some of the key project themes and brief descriptions of student projects that emerged across the cohort. The project implementations can be found in the linked GitHub repositories.
Theme 1: Innovations in Visual Learning for Human Representation
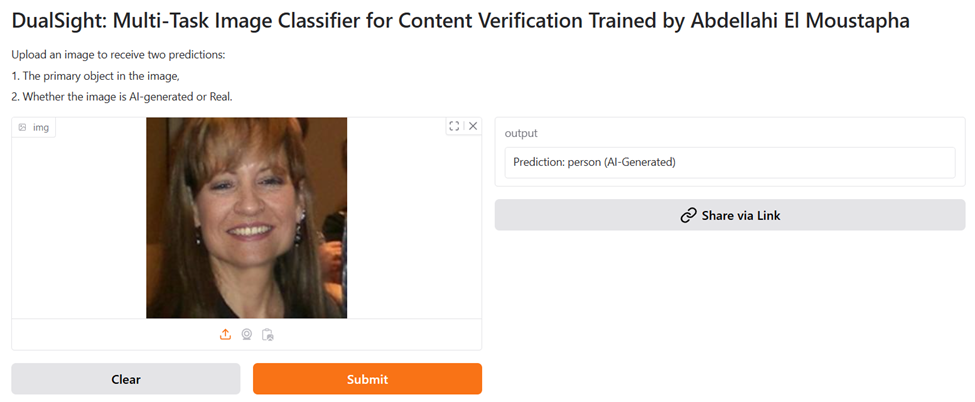
In response to the growing need for detecting AI-generated content, one of our students, Abdellahi El Moustapha developed DualSight, a multi-task image classification system that combines object recognition and authenticity verification. Leveraging YOLO-based pseudo-labeling for object detection and a ResNet-50 backbone for shared feature extraction, the model was trained on a large dataset of approximately 152,000 images, achieving high accuracy (85–89%) in distinguishing real from synthetic images. An interactive demo is deployed on HuggingFace, with future plans to refine labeling strategies and improve detection performance. Project repository: https://github.com/Abmstpha/dual-sight-project

Another student Ahmed Ben Aissa’s project addresses a common e-commerce challenge—predicting clothing sizes based on user-submitted images. His two-stage system first uses a modified EfficientNet model to estimate body measurements from front and side views. Then, a CatBoost Regressor maps these measurements to standard clothing sizes. The models are trained on BodyM dataset (1) and e-commerce data. Through this project we could identify limitations in available open source clothing datasets for computer vision (e.g lack of clothing type specific size features) and potentials to develop brand-specific models, augmented reality integration, and improved data privacy. Project repository: https://github.com/zaizou1003/Predicting_Sizes_CV

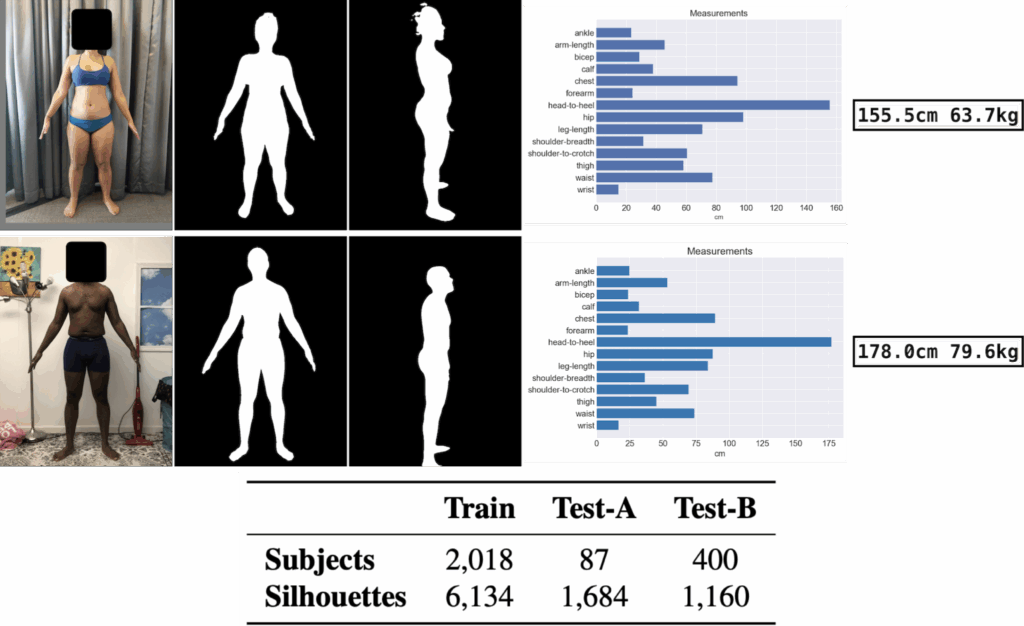

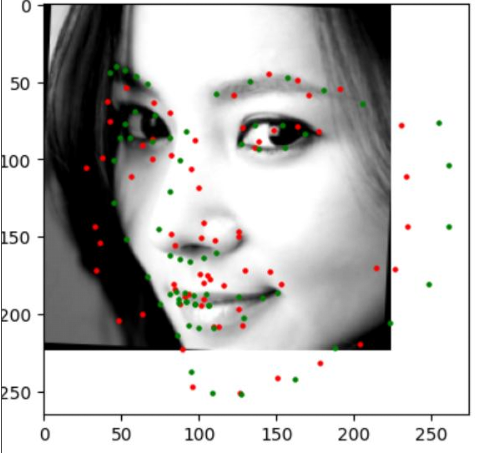
Fig 2(a) Features of the BodyM dataset with body measurement profiles (b) Face landmark detection project by Darryl: green points: ground truth landmarks. red points: predicted landmark
Other projects in this category include Oussama Bouriga’s real-time emotion recognition system using a custom CNN trained on FER-2013 dataset to detect five emotions from real time webcam video input (https://github.com/Oussamabouriga/emotion_detection ) . Darryl Towa developed a facial landmark detection model based on a modified ResNet18 that predicts 68 landmark points from grayscale images, trained on the iBUG 300-W (2) dataset. Baptiste Langlois’s project aims to enhance construction site safety using a YOLOv5-based model trained on Roboflow dataset to detect helmets and heads.
Theme 2: Activity recognition in complex and dynamic environments
This category attracted some remarkable projects from students such as the one by Likhita Yerra which focuses on detecting and analyzing chess moves from video using computer vision and NLP. It uses YOLOv8 to identify all 12 chess pieces on an 8×8 board, tracks movements, and converts them into standard chess move notation. Based on these, a GPT-4 LLM is used to generate game commentary for users to understand chess moves . It is deployed as an interactive Streamlit app where users can upload videos for running the pipeline
. She named the project “chess vision narrator” and the implementation may be found at https://github.com/LikhitaYerra/Chess-Vision-Narrator Future plans include real-time processing, dataset expansion, integration with Stockfish (3) for move evaluation, and multi-platform deployment. A video demo showcases the pipeline in action, highlighting the blend of technical accuracy and engaging commentary.



The project by Remi Allam showcased an intuitive, touchless gaming experience powered by computer vision techniques. She designed a gesture based ping pong game that uses Google’s MediaPipe library (4) for real-time hand tracking, allowing players to control paddles via webcam without physical contact. Built with Python, OpenCV, and MediaPipe, the game features smooth paddle control and dynamic ball movement. It maps palm coordinates to vertical paddle movements and includes mechanisms for collision detection, scoring, and game resets. The implementation can be found at https://github.com/Remi0719/ping-pong
Thibault Goutorbe proposed a hand gesture-based musical instrument control, which leverages real-time computer vision to enable interactive music creation. Using MediaPipe for hand landmark detection and OpenCV for video processing, the system tracks both hands, counts raised fingers, and maps hand positions to musical parameters like instrument selection, pitch, and note value. Using these gestures, MIDI messages are sent to control sound output on synthesizers such as Qsynth (5) Project repository : https://github.com/Suponjibobu19/computervision2s
Another student, Rohit Singh’s fitness tracking app, applies computer vision for real-time exercise monitoring, focusing on squats, bench press, and deadlifts. Built with Flask, it uses MediaPipe for pose detection and a PyTorch model for classifying exercises based on joint movements. The app includes features like live rep counting, form analysis, and data logging. It also supports secure login and real-time predictions through APIs, deployable via Waitress or Gunicorn. The implementation can be found in https: //github.com/rohit91-gif/fitness_project

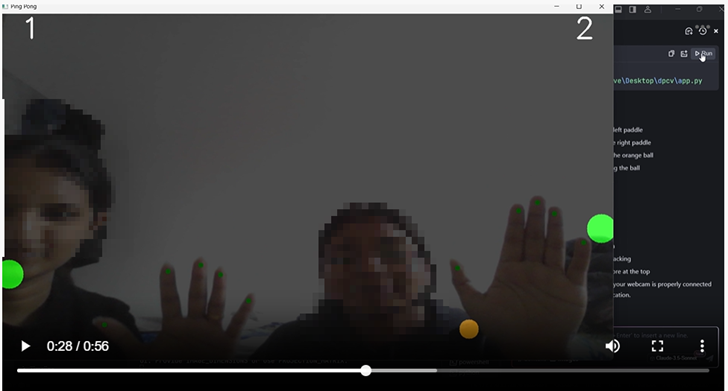



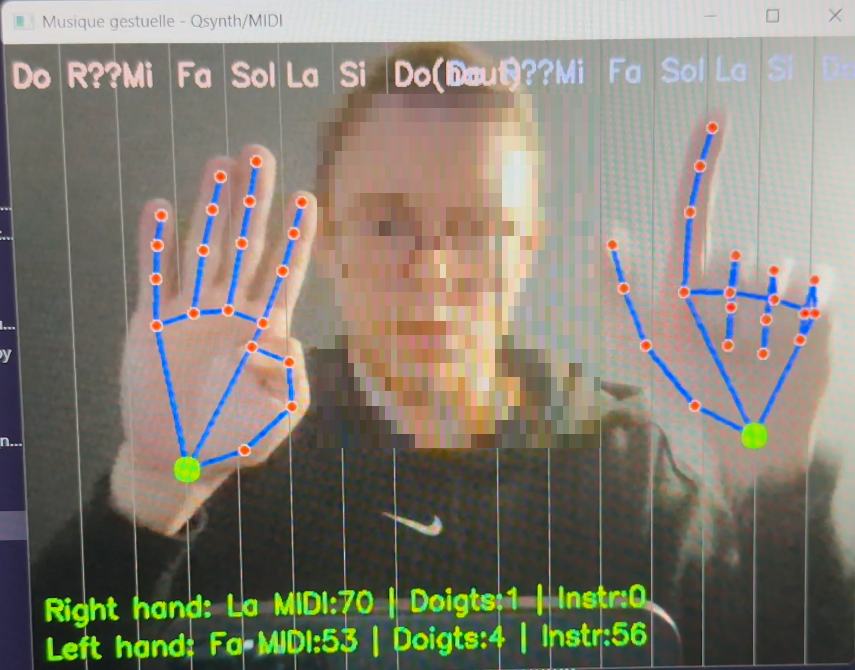
Fig 5. (a) The computer vision based fitness tracker application by Rohit Singh which accurately detects and counts exercise poses under unconstrained video background conditions (b) The hand gesture detector of Thibault Goutorbe which can be used to control musical notes.
Theme 3: Experimenting with computer vision model architectures
Shafiya Kausar explored the possibility of modifying the DETR (DEtection TRansformer) architectures with a custom mesh network layer and tested it with the COCO 2017 dataset. The project integrates a mesh network layer—a convolutional module aimed at refining spatial features—after the ResNet-50 backbone of DETR to potentially improve localization accuracy. The system successfully performs inference on COCO validation images, producing qualitatively sound bounding box predictions. Future directions include mesh architecture optimization, full-scale training, deployment for real-world applications, and exploration of advanced spatial modeling techniques like graph or attention-based layers.


The project by Li Tong explores brain tumor segmentation using custom 2D U-Net architecture using the MONAI framework (7) targeting multi-modal MRI scans from the BraTS 2020 dataset. The modular pipeline built within Tong’s project supports both standard and MONAI-based U-Nets. This can be found in her repository: https://github.com/tongli-yn/brats-segmentation-unet
Conclusion
For my Deep Learning for Computer Vision course this semester I believed that incorporating hands-on projects would effectively complement the core concepts I taught in class. I saw this as an opportunity for students to develop original ideas and sharpen their problem-solving skills that are essential in the fast-evolving landscape of deep learning applications. The results as seen above confirmed this, as the students delivered projects that went well beyond textbook exercises, applying theory to meaningful real-world problems while exploring topics they were genuinely passionate about. Notably, many of these projects are open source and designed for reproducibility, reflecting commitment of students towards transparency and collaborative progress. Ultimately, this hands-on approach allowed students to be active learners and capable contributors in the field of deep learning and computer vision.